こんにちは、小澤です。
前回は、SVM(サポートベクターマシン)を用いた分類について解説しました。今回は、決定木(Decision Tree)を使用して、データを段階的に分割しながら分類を行う方法を説明します。
なお、今回の内容は、教科書『Pythonによる新しいデータ分析の教科書(第2版)』の4.4.2章「分類」の決定木(236〜241ページ)の箇所です。
1. 決定木(Decision Tree)とは?
決定木(Decision Tree)は、データを「はい / いいえ」の質問を繰り返しながら、樹木のような階層構造で分割していくことで、分類や回帰を行う機械学習アルゴリズムです。
2. 決定木のイメージ
決定木は、連続する条件分岐によってデータを分類します。
たとえば、以下のようにデータを分類していきます。
- 「花びらの長さは 2.5cm より長いですか?」 → はい / いいえ
- 「はい」 の場合 → 次の質問へ
- 「いいえ」 の場合 → Iris-setosa と予測
- 次の質問:「花びらの幅は 1.5cm より広いですか?」 → はい / いいえ
このように、一連の質問を繰り返して、最終的な分類結果に到達します。これが「決定木」の基本的な考え方です。
3. 決定木の構造
- ルートノード (Root Node)
最初の質問をするノードです。データ全体を対象に、最も情報を分ける特徴量で分割します。 - 内部ノード (Internal Node)
中間の質問ノードです。条件に基づいてデータをさらに分割します。 - 葉ノード (Leaf Node)
最終的な分類結果が表示されるノードです。ここに到達したデータは、特定のクラスラベル(例:Iris-setosa)を持ちます。
4. scikit-learnによる決定木の実装
scikit-learn には、決定木を簡単に使えるクラス DecisionTreeClassifier が用意されています。
以下は、Irisデータセットを使用して、決定木モデルを構築・評価する例です。
4.1 データの準備
Irisデータセットを読み込み、学習データ(80%)とテストデータ(20%)に分割します。
| from sklearn import datasets from sklearn.model_selection import train_test_split # データセットのロード iris = datasets.load_iris() X = iris.data # 特徴量 y = iris.target # ラベル # データの分割(80%を学習用、20%をテスト用) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y) |
コードの説明
- datasets.load_iris()
scikit-learn に組み込まれているIrisデータセットをロードしています。
X には 特徴量(花びらやがく片の長さ・幅)を、y にはラベル(花の種類)を格納します。 - train_test_split()
データを学習用(80%)とテスト用(20%)に分けます。
stratify=y を指定することで、クラスの比率を保ったまま分割しています。
random_state=42 を設定することで、再現性のある分割が可能になります。
なぜこの設定にするのか?
- test_size=0.2
データの20%をテスト用にすることで、モデルの性能を未知のデータで評価できます。テストデータが少なすぎると性能の評価が不安定になり、多すぎると学習に使えるデータが減りモデルの精度が落ちるため、20%前後がバランスの良い値とされています。 - stratify=y
クラスの比率を保ったままデータを分割することで、偏りのない評価が可能になります。特に、クラスの割合が均等でない場合に、モデルの性能を正確に評価できます。 - random_state=42
データの分割が毎回ランダムに行われると、結果が異なってしまうため、再現性を確保するために設定します。同じ乱数シードを使うことで、常に同じ分割結果を得ることができます。
4.2 決定木モデルの作成と学習
| from sklearn.tree import DecisionTreeClassifier # 決定木モデルの作成 model = DecisionTreeClassifier(criterion=’gini’, max_depth=3, random_state=42) model.fit(X_train, y_train) |
コードの説明
- DecisionTreeClassifier
scikit-learn の 決定木モデルを作成するクラスです。
criterion=’gini’ → ジニ不純度を基準に分割(デフォルト)
max_depth=3 → 決定木の深さを 3 に制限し、過学習を防止。
random_state=42 を設定して、分割の再現性を確保。 - fit()
学習用データ(X_train と y_train)を使って、決定木モデルの訓練を行います。この段階で、データのパターンを学習し、条件分岐のルールを決定します。
なぜこの設定にするのか?
- criterion=’gini’
ジニ不純度を基準にすることで、純度の高いノードを作成できます。
entropy を与えてエントロピーを基準にすることも可能ですが、計算量が多くなるため、gini の方が高速に動作します。 - max_depth=3
決定木が深くなりすぎると過学習のリスクがあるため、適度な深さに制限します。一般的には、3〜5程度がバランスの良い深さとされています。 - random_state=42
決定木の分岐はランダム性を含むため、同じモデルを再現するために設定します。こうすると、実験結果の一貫性を保つことができます。
4.3 予測と評価
決定木モデルを作成・学習したら、テストデータを使って予測を行い、その結果を評価します。評価指標には、混同行列(Confusion Matrix)や分類レポート(Classification Report)を用います。
| from sklearn.metrics import classification_report, confusion_matrix # テストデータで予測 y_pred = model.predict(X_test) # 結果の評価 print(“【混同行列】”) print(confusion_matrix(y_test, y_pred)) print(“\\n【分類レポート】”) print(classification_report(y_test, y_pred, target_names=iris.target_names)) |
コードの説明
- predict()
テスト用データ(X_test)を使って、学習済みモデルによる分類の予測を行います。予測結果は y_pred に格納されます。y_pred には、各サンプルに対して予測されたクラスラベルが含まれています。
ここでは、predict(X_test)と、テストデータを使って予測することで、未知のデータに対するモデルの性能を確認できます。学習に使用したデータで評価すると、過学習の影響を受けるため、別のデータ(テストデータ)を用いることで汎化性能を評価します。 - confusion_matrix()
実際のラベル(y_test)と予測ラベル(y_pred)を比較し、混同行列を表示します。混同行列には、クラスごとの正解数と誤分類の数が表示されます。
クラスごとの正解数と誤分類の数を確認することで、どのクラスで誤分類が多いかを分析できます。特に、クラス間で不均衡がある場合に有効です。 - classification_report()
精度(Precision)、再現率(Recall)、F1スコアを出力します。target_names を指定して、Irisデータセットの クラス名(Iris-setosa, Iris-versicolor, Iris-virginica)を表示しています。
精度(Precision)、再現率(Recall)、F1スコアを確認することで、分類モデルの性能を総合的に評価できます。F1スコアは、精度と再現率のバランスを表すため、不均衡データの評価に適しています。
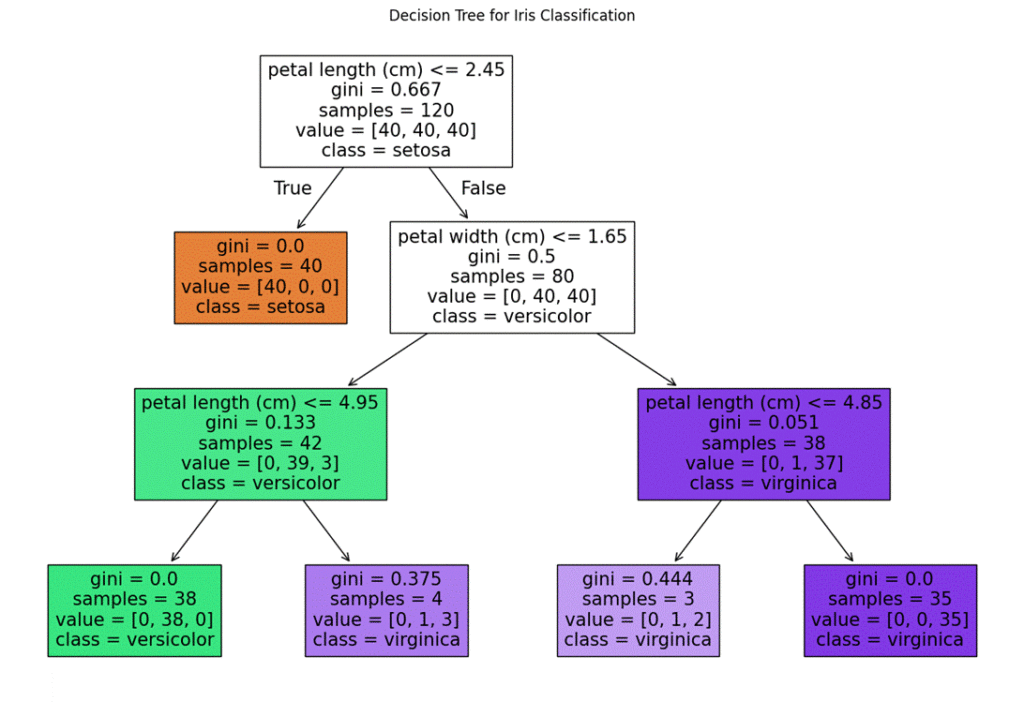
4.4 決定木の可視化
決定木は、樹木のような階層構造を持っているため、可視化することで条件分岐のルールが直感的に理解できます。ここでは、scikit-learn の plot_tree()を使用して、決定木をグラフとして表示します。
| from sklearn import tree import matplotlib.pyplot as plt # 決定木の可視化 plt.figure(figsize=(15, 10)) tree.plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True) plt.title(“Decision Tree for Iris Classification”) plt.show() |
コードの説明
- plt.figure(figsize=(15, 10))
グラフのサイズを設定します。
figsize=(15, 10) で、横15インチ、縦10インチのサイズに設定しています。 - plot_tree()
決定木の構造を可視化します。
feature_names には特徴量の名前を、class_names にはクラスラベルを表示しています。filled=True にすることで、クラスごとにノードに色がつき、どのクラスに分類されたかが視覚的にわかりやすくなります。 - plt.title()
グラフのタイトルを設定します。今回は “Decision Tree for Iris Classification” としています。 - plt.show()
グラフを表示します。
4.5 実行結果の解説
混同行列の出力

- Iris-setosa はすべて正しく分類されています。
- Iris-versicolor は 1 件、Iris-virginica に誤分類されています。
- Iris-virginica はすべて正しく分類されています。
分類レポートの出力
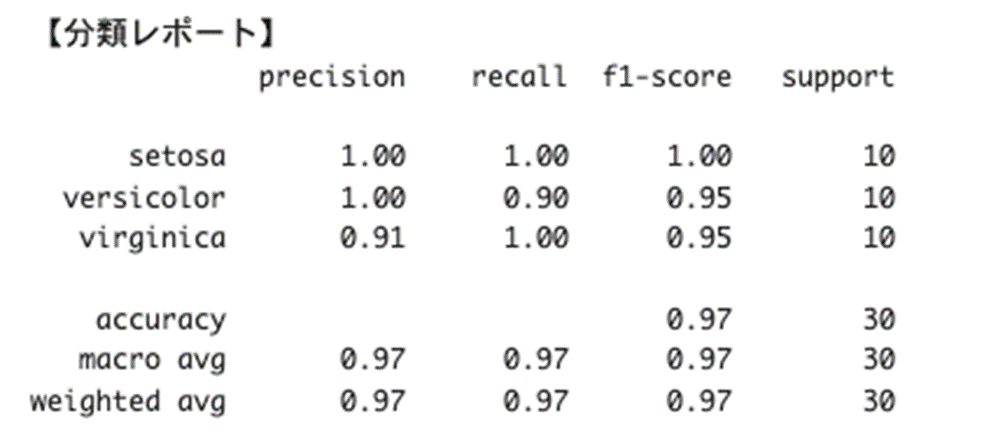
- Iris-setosa
Precision(精度) = 1.00:予測がすべて正解
Recall(再現率) = 1.00:実際の Iris-setosa をすべて正しく予測
F1-score = 1.00:完璧なバランス - Iris-versicolor
Precision(精度) = 1.00:Iris-versicolor と予測したものはすべて正解
Recall(再現率) = 0.90:実際の Iris-versicolor の 10 件中 9 件を正しく予測
F1-score = 0.95:高いバランスを維持 - Iris-virginica
Precision(精度) = 0.91:予測した Iris-virginica のうち、91% が正解
Recall(再現率) = 1.00:実際の Iris-virginica をすべて正しく予測
F1-score = 0.95:バランス良好
決定木の可視化
全体の評価
- Accuracy(正答率) = 0.97 (97%)
全体の予測のうち、97% が正解 しており、非常に高い精度を持つモデルです。 - Macro avg と Weighted avg がともに 0.97
クラス間のバランスが良いことを示しています。特定のクラスに偏った予測がない、偏りのないモデルです。
5. まとめ
決定木は、直感的で解釈がしやすく、可視化が容易なモデルです。scikit-learn の DecisionTreeClassifier を使用することで、シンプルなコードで実装できるという利点があります。しかし、過学習しやすいというリスクもあります。
過学習を防ぐためには、いくつかの工夫が必要です。まず、木の深さを制限する(max_depth)ことで、モデルが複雑になりすぎるのを防ぎます。さらに、ノードの最小サンプル数を設定する(min_samples_split, min_samples_leaf)ことで、過剰に細かい分割を抑えることができます。これにより、ノイズに過剰に適応することを防ぎ、モデルの汎化性能を向上させることが可能です。
また、特徴量の選択を工夫することも有効です。不要な特徴量やノイズを含むデータを取り除くことで、モデルの精度を保ちつつ、過学習のリスクを軽減できます。過学習のリスクを認識し、これらの工夫をすることで、決定木の性能を最大限に引き出せるでしょう。
次回は、回帰モデルと次元削減、特に「主成分分析(PCA)」について解説します。これらの手法では、データのパターンをより深く理解し、効果的に情報を圧縮することが可能になります。回帰モデルを用いた予測や次元削減を通じたデータの可視化など、応用範囲が広がります。次回もお楽しみに。