こんにちは、小澤です。
今回からscikit-learnを用いた分類と回帰について解説していきます。教科書『Pythonによる新しいデータ分析の教科書(第2版)』では、4.4.2章「分類」と4.4.3章「回帰」(225〜245ページ)の箇所です。
分類と回帰を理解するには、その基礎となる「教師あり学習」の概念を押さえることが重要です。そこで、今回は教師あり学習の基本について解説し、分類や回帰などへの適用方法を学んでいきましょう。
教師あり学習とは?
教師あり学習(Supervised Learning)は、機械学習の一種で、「入力データ」と「正解ラベル」がペアになったデータセットを用いてモデルを学習させる手法です。
教師あり学習の特徴
- 教師あり学習の目的は、モデルにデータのパターンを学習させ、未知のデータに対して正確なラベルを予測できるようにすることです。このため、入力データ(特徴量)とそれに対応する正解(ラベル)のペアからなるデータセットを使用し、モデルは各クラスの特徴を学習します。代表的な例として、以下のようなデータセットがあります。
- Irisデータセット:花の特徴(花びらの長さ・幅)から花の種類を分類
- MNISTデータセット:手書き文字画像を対応する数字(0~9)に分類
- 特徴量は、データポイントを表すための数値やカテゴリ情報です。例えば、Irisデータセットには、花の形状に関連する以下のような測定値が含まれ、花を分類するための指標を提供します。
- 花びらの長さ(Petal Length)
- 花びらの幅(Petal Width)
- がく片の長さ(Sepal Length)
- がく片の幅(Sepal Width)
- ラベルは、データポイントが属するクラス(カテゴリ)を示します。Irisデータセットには、以下の3つの花の種類が含まれています。
- Iris-setosa:花びらが小さく幅広い特徴を持つ
- Iris-versicolor:中間的なサイズと形状を示す
- Iris-virginica:花びらが細長い特徴を持つ
教師あり学習の流れ
教師あり学習は、以下のステップで進めます。
1.データ収集と準備
- ラベル付きデータセットを用意します。例えば、Irisデータセットでは花びらの長さや幅(特徴量)が「Iris-setosa」などの種類(ラベル)とペアになっています。
- 欠損値の補完、特徴量のスケーリング、カテゴリ変数のエンコーディングなどを行い、データをモデルが扱いやすい形に整えます。
2.学習
- 学習データ(入力データとラベル)をモデルに与えてトレーニングを行います。モデルはデータのパターンを学び、未知のデータに対して適切な予測ができるようになります。
3.予測
- 学習済みモデルに未知のデータ(特徴量)を入力すると、モデルが予測したラベルや値を出力します。
4.評価
- モデルの性能をテストデータを用いて評価します。評価指標には以下のようなものがあります。
- 正答率(Accuracy):全予測のうち正解した割合。
- F1スコア:精度と再現率のバランスを評価。
- 平均二乗誤差(MSE):回帰タスクで、予測値と実際の値の差を測定。
教師あり学習の主要タスク
1.分類(Classification)
分類は、入力データをあらかじめ定義されたカテゴリ(離散値)に割り当てるタスクです。出力は、特定のクラスラベル(カテゴリ)です。分類は、以下のような特徴を持ちます。
- 特徴
- 出力形式:データポイントごとに1つのクラスラベル(例:スパム・非スパム)を割り当てる。
- 離散的な結果:出力が連続的な数値ではなく、有限のカテゴリ(離散値)で表現される。
- ラベル付きデータ:学習データに正解ラベルが含まれている(教師あり学習)。
- 種類
- 2クラス分類:
- 出力が2つのクラスラベルのみの場合。
- 例:メールが「スパム」または「非スパム」。
- 多クラス分類:
- 出力が3つ以上のクラスラベルを持つ場合。
- 例:Irisデータセットで花を3つの種類に分類(Iris-setosa、Iris-versicolor、Iris-virginica)。
- 2クラス分類:
- 適用例
- 医療診断:病気が「陽性」か「陰性」かを分類。
- 画像認識:写真に写っている動物を「犬」「猫」「鳥」などに分類。
- テキスト分類:商品レビューを「ポジティブ」「ネガティブ」「ニュートラル」に分類。
- 分類アルゴリズム
- サポートベクターマシン(SVM)
- 決定木
- ランダムフォレスト
- k近傍法(k-NN)
- ロジスティック回帰
2.回帰(Regression)
回帰は、入力データに基づいて連続値(数値)を予測するタスクです。分類とは異なり、出力は連続的な数値で表現されます。
- 特徴
- 出力形式:出力はスカラー値(連続値)で、数値として予測される。
- 離散的な結果:出力は特定のカテゴリではなく、値の範囲に属する。
- ラベル付きデータ:入力データと正解ラベル(数値)のペアが必要(教師あり学習)。
- 適用例
- 住宅価格予測:家の特徴(面積、立地条件など)を基に価格を予測。気温予測:過去のデータを基に未来の気温を予測。
- 回帰アルゴリズム
- 線形回帰ラッソ回帰、リッジ回帰サポートベクターレグレッション(SVR)決定木回帰
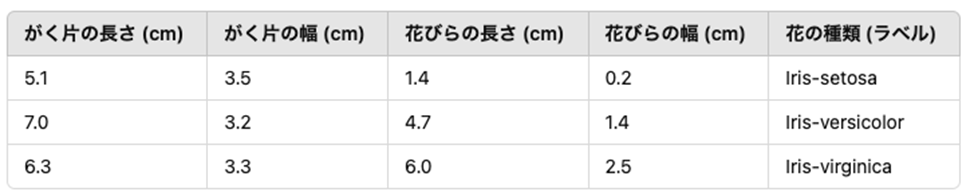
Irisデータセットの構造
例えば、Irisデータセットは以下のようなデータセットです。特徴量を基に、モデルはデータポイントを正しいラベルに分類します。
まとめ
教師あり学習は、入力データとラベルの関係をモデルが学習することで、未知のデータに対して予測をおこなう手法です。その中でも分類と回帰は、出力形式(カテゴリまたは数値)に応じて適切なアルゴリズムを選択する必要があります。
次回からは、scikit-learnを使用して分類と回帰モデルを構築し、実際のデータセットでそれらを活用する方法を具体的に解説していきます。ぜひお楽しみに。