こんにちは、小澤です。
前回から、データ分析を行うためのライブラリであるpandasを取り上げています。pandasは、データの入手や加工など多くのデータ処理に使われています。
今回説明するのは、pandasでのデータの読み込み、書き込み、整形です。教科書『Pythonによる新しいデータ分析の教科書(第2版)』では、4.2章「pandas」のデータの読み込み・書き込み、データの整形(145ページ〜160ページ)の箇所です。
データの読み込み
1. CSVファイルからデータを読み込む
CSVファイルからデータを読み込むには、pandasのread_csv関数を使用します。この関数は、CSVファイルを読み込み、DataFrameオブジェクトとしてデータを返します。
| import pandas as pd df = pd.read_csv(‘data/202204health.csv’, encoding=’utf-8′) print(df.head()) # データの最初の5行を表示 |
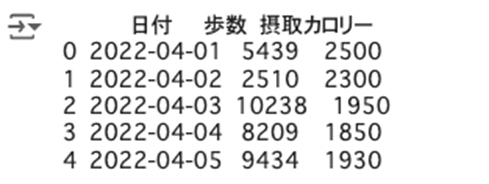
read_csv関数の主なパラメータは以下です。
- filepath_or_buffer:読み込むCSVファイルのパスまたはURL。
- encoding:ファイルの文字エンコーディング。デフォルトはUTF-8。
- sep:デリミタ(区切り文字)。デフォルトはカンマ。
- header:ヘッダー行のインデックス。デフォルトは0。
- names:カラム名のリスト。データにヘッダーがない場合に使用。
- index_col:インデックスに使用する列。
- parse_dates:日付として解析する列。
2. Excelファイルからデータを読み込む
Excelファイルからデータを読み込むには、pandasのread_excel関数を使用します。この関数も、DataFrameオブジェクトとしてデータを返します。
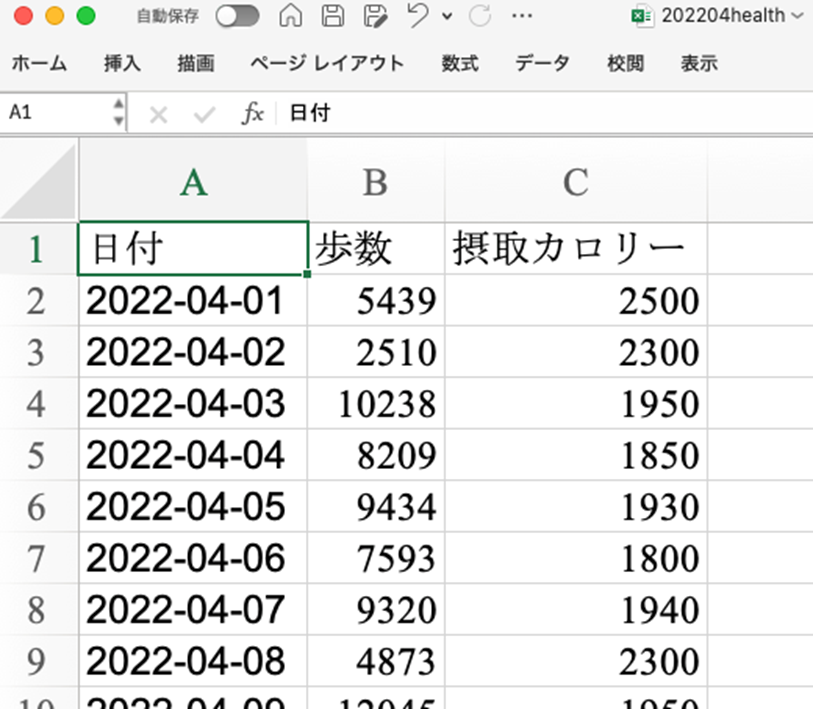
| import pandas as pd df = pd.read_excel(‘data/202204health.xlsx’) print(df.head()) # データの最初の5行を表示 |

read_excel関数の主なパラメータは以下です。
- io:読み込むExcelファイルのパスまたはURL。
- sheet_name:読み込むシートの名前またはインデックス。複数シートの場合はリストで指定。
- header:ヘッダー行のインデックス。デフォルトは0。
- names:カラム名のリスト。データにヘッダーがない場合に使用。
- index_col: インデックスに使用する列。
- parse_dates: 日付として解析する列。
3. WebのHTMLからテーブルを読み込む
WebサイトのHTMLからテーブルデータを読み込むこともできます。読み込むには、read_html関数を使用します。この関数は、指定したURLまたはファイルパスのHTMLからテーブル要素を抽出し、DataFrameオブジェクトとして返すものです。例えば、ウィキペディアのトップレベルドメイン一覧のページからテーブルを抽出するコードは以下です。
| import pandas as pd url = “<https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%83%E3%83%97%E3%83%AC%E3%83%99%E3%83%AB%E3%83%89%E3%83%A1%E3%82%A4%E3%83%B3%E4%B8%80%E8%A6%A7>” tables = pd.read_html(url, flavor=”html5lib”) df = tables[4] df |

ここでは、HTMLを解析するためのパーサーとしてhtml5libを使用することを指定しています。html5libは、Python用のHTMLパーサーの一つで、HTML5標準に準拠している、柔軟なパーサーです。html5libを使用すると、さまざまな形式のHTML文書を正確に解析することができます。この他にも、lxmlという非常に高速なパーサーもあります。
read_html関数を使って、ページからテーブルをすべて読み込んだら、ページ内の5番目のテーブル(0インデックス)を取得し、データフレームに格納し、表示しています。
データの書き込み
1. CSVファイルへの書き込み
DataFrameをCSVファイルに書き出すにはto_csv()メソッドを使います。出力ファイル名を指定するほか、「index=False」のオプションを指定すると、CSVファイルにインデックス(行番号)を書き出さないようにできます。また、エンコーディングも指定できます。
| df.to_csv(“data/write_data.csv”, index=False, encoding=”utf-8″) |
2. Excelファイルへの書き込み
Excelファイルに書き出すにはto_excel()メソッドを使います。
| df.to_excel(“data/write_data.xlsx”) |
3. その他の形式への書き込み
CSVファイル、Excelファイルへの書き込みのほか、以下のようなメソッドがあります。
- to_sql:データベースへの書き込み
- to_json:JSONファイルへの書き込み
- to_html:htmlファイルへの書き込み
- to_latex:LaTeX形式への書き込み
データの整形
DataFrameに対する条件抽出、並べ替え、列の追加・削除なども簡単に行うことができます。
1. 条件抽出
locを使用して、行と列のラベルに基づいてデータを抽出します。特定の条件に基づいてデータをフィルタリングしたり、特定の行と列を選択したりできます。
| df = pd.read_excel(‘/content/data/202204health.xlsx’) # 単一条件の抽出 filtered_df = df.loc[df.loc[:, “歩数”] >= 10000, :] # 複数条件の抽出 filtered_df = df.loc[(df.loc[:, “歩数”] >= 10000) & (df[“摂取カロリー”] <= 1900), :] filtered_df |
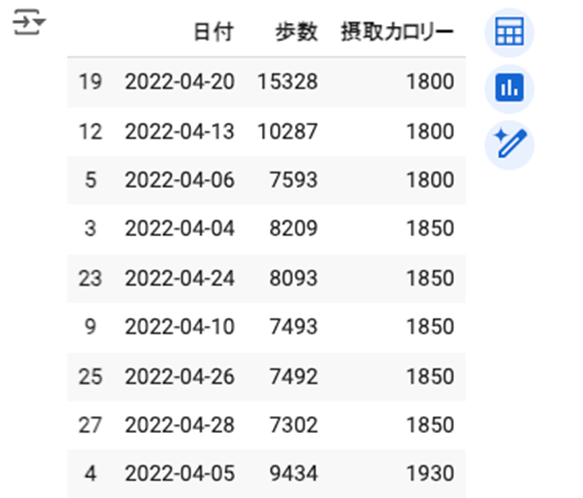
2. 並べ替え
sort_values()メソッドを使うと、指定した列の値に基づいてDataFrameを並べ替えることができます。ascending引数には、True(昇順)またはFalse(降順)を指定します。また、複数の列を基準にして並べ替える場合は、by引数に列名のリストを渡し、ascending引数に並べ替え順序のリストを渡します。
| # データの並べ替え(昇順) sorted_df = df.sort_values(by=”歩数”) # データの並べ替え(降順) sorted_df = df.sort_values(by=”歩数”, ascending=False) # 複数列での並べ替え sorted_df = df.sort_values(by=[“摂取カロリー”, “歩数”], ascending=[True, False]) sorted_df |
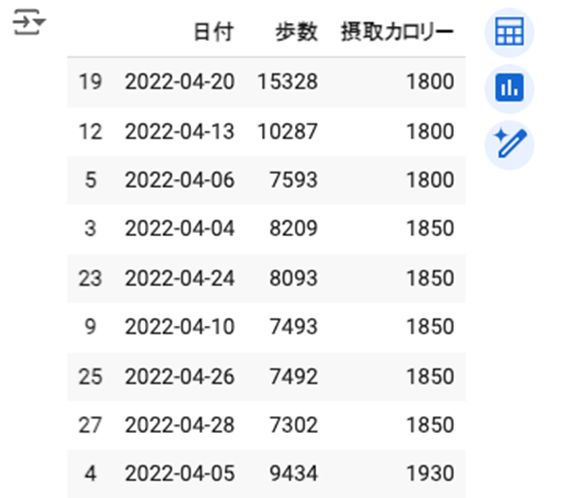
3. 列の追加・削除
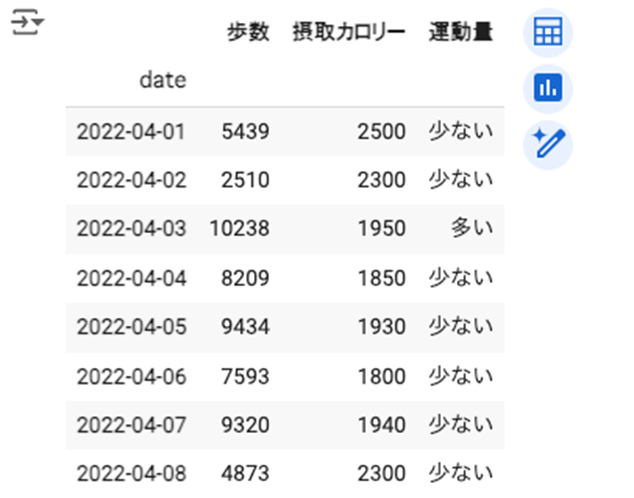
条件に基づいて新しい列を追加できます。ここでは、歩数が10000以上の行に対して「運動量」列として「多い」、10000未満の行に対して「運動量」列に「少ない」に設定します。
| df.loc[df.loc[:, “歩数”] >= 10000, “運動量”] = “多い” df.loc[df.loc[:, “歩数”] < 10000, “運動量”] = “少ない” |
また、「日付」列を datetime型に変換し、新しい列「date」として追加、インデックスに設定します。そして、元の「日付」列をdropメソッドを使って削除します。
| df.loc[:, “date”] = df.loc[:, “日付”].apply(pd.to_datetime) df = df.set_index(“date”) df = df.drop(“日付”, axis=1) df |
まとめ
今回は、pandasを使用したデータの読み込み方法、書き込み方法、データの整形方法について説明しました。具体的には、CSVファイルやExcelファイルからのデータ読み込み、データのフィルタリングや並べ替えの方法、データの型変換や計算による列の追加について解説しました。pandasを使った基本的なデータ操作について理解できたと思います。
次回は、pandasを使ったさらに複雑なデータ操作について説明します。次回もお楽しみに。