こんにちは、小澤です。
前回まで、数値計算に特化したサードパーティ製のライブラリであるNumPyについて説明してきました。NumPyは、その強力な機能と柔軟性から、Pythonでの科学計算やデータ分析における必須のツールとなっています。使い方をぜひマスターしてください。
さて、今回からはPandasを解説していきます。pandasは、データ解析を行うためのデータ操作ライブラリで、データの読み込みからクリーニング、分析、変換、可視化までを行うことができるものです。教科書『Pythonによる新しいデータ分析の教科書(第2版)』では、4.2章「pandas」(135ページ〜177ページ)の部分です。今回は、その前半部分(135ページ〜145ページ)を主に解説します。
pandasの概要
pandasは、Pythonでデータ解析を行うためのデータ操作ライブラリです。データの読み込み、クリーニング、分析、変換、可視化など、データサイエンスや機械学習のプロジェクトで頻繁に使用されています。
主な特徴は以下です。
1.高性能なデータ構造
○シリーズ(Series)
一次元のデータ構造。リストや配列に似ているが、インデックスを持つ。
○データフレーム(DataFrame)
行と列で構成された2次元のデータ構造。ExcelやSQLのテーブルに似ている。
2.データ操作の容易さ
○データのフィルタリング、グルーピング、集計、マージ、結合などが簡単に行える。
3.データのクリーニング
○欠損値の処理、データ型の変換、重複の削除など、データ前処理の機能が豊富。
4.多種多様なデータソースからの読み込み
○CSV、Excel、SQL、JSON、HTMLなど、様々な形式のデータを読み込むことができる。
5.高速な計算
○NumPyベースの計算機能により、大規模データの操作でも高速に処理できる。
pandasを使用するには、以下のようにインポートします。pdで呼び出せるようにしましょう。
| import pandas as pd |
シリーズ(Series)とデータフレーム(DataFrame)
pandasのシリーズ(Series)とデータフレーム(DataFrame)は、データ分析や操作において非常に重要な構造です。それぞれの特徴と使い方について説明します。
シリーズ(Series)
シリーズは、1次元の配列状のデータ構造で、データのラベル(インデックス)を持つことができます。シリーズは同じデータ型の要素を持つことが一般的です。
1.特徴
○1次元のデータ構造
○ラベル(インデックス)を持つ
○同じデータ型の要素を持つ
2.使い方
| import pandas as pd # シリーズを作成 data = [10, 20, 30, 40] index = [‘a’, ‘b’, ‘c’, ‘d’] series = pd.Series(data, index=index) print(series) |

データフレーム(DataFrame)
データフレームは、2次元の表形式のデータ構造で、行と列の両方にラベル(インデックスとカラム)を持つことができます。各列はシリーズとして扱われ、異なるデータ型を持つことができます。
1.特徴
○2次元のデータ構造
○行と列にラベル(インデックスとカラム)を持つ各列はシリーズとして扱われ、異なるデータ型を持つことができる
2.使い方
| import pandas as pd # データフレームを作成 data = { ‘Name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’], ‘Age’: [24, 27, 22, 32], ‘City’: [‘New York’, ‘Los Angeles’, ‘Chicago’, ‘Houston’] } df = pd.DataFrame(data) print(df) |

シリーズとデータフレームの違い
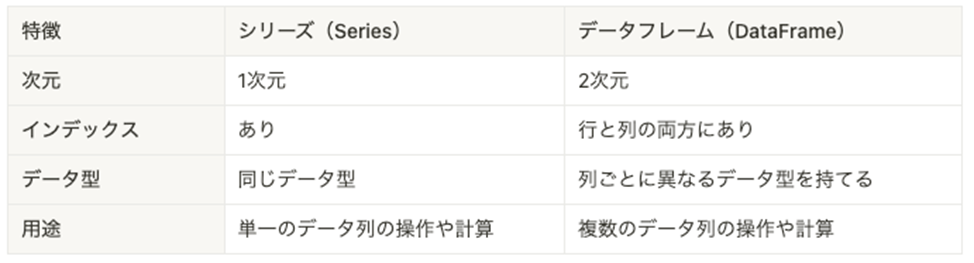
シリーズとデータフレームの変換
シリーズをデータフレームに変換することも、データフレームの列をシリーズとして扱うことも可能です。
| # シリーズからデータフレームへの変換 series = pd.Series([10, 20, 30, 40], index=[‘a’, ‘b’, ‘c’, ‘d’]) df_from_series = series.to_frame(name=’Values’) print(df_from_series) # データフレームの列をシリーズとして扱う df = pd.DataFrame({ ‘A’: [1, 2, 3], ‘B’: [4, 5, 6] }) series_from_df = df[‘A’] print(series_from_df) |

データの抽出
pandasのlocを使うと、データフレームから特定のデータを抽出できます。locでは、行と列をラベルベースで指定してデータを抽出します。
ここでは、以下のサンプルデータを使います。
| # サンプルデータの作成 data = {‘Name’: [‘Alice’, ‘Bob’, ‘Charlie’], ‘Age’: [25, 30, 35], ‘City’: [‘New York’, ‘Los Angeles’, ‘Chicago’]} df = pd.DataFrame(data, index=[‘a’, ‘b’, ‘c’]) |
- 行ラベルを指定して抽出
| # ‘a’行のすべての列を抽出 print(df.loc[‘a’, :]) |

- 行と列ラベルを指定して抽出
| # ‘a’行の ‘Name’ 列を抽出 print(df.loc[‘a’, ‘Name’]) # ‘a’行の ‘Name’ 列と ‘Age’ 列を抽出 print(df.loc[‘a’, [‘Name’, ‘Age’]]) |

- 複数の行を抽出
| # ‘a’ と ‘b’ 行のすべての列を抽出 print(df.loc[[‘a’, ‘b’], :]) |

- 行ラベルと列ラベルの範囲を指定して抽出
| # ‘a’ から ‘b’ 行、’Name’ から ‘Age’ 列を抽出 print(df.loc[‘a’:’b’, ‘Name’:’Age’]) |

- 条件を満たす行を抽出
| # Age 列が30以上の行を抽出 print(df.loc[df[ ‘Age’ ] >= 30, :]) |

- 複数の条件を使った抽出
| # Age が30以上で、City が ‘New York’ の行を抽出 print(df.loc[(df[‘Age’] >= 30) & (df[‘City’] == ‘New York’), :]) |

また、ilocを使用すると、データフレームからインデックス(位置)ベースでデータを抽出できます。ilocでは整数インデックスを使って行や列を指定します。
7. 行インデックスを指定して抽出
| # 0番目の行のすべての列を抽出 print(df.iloc[0, :]) |

- 複数の行を抽出
| # 0番目と2番目の行のすべての列を抽出 print(df.iloc[[0, 2], :]) |

- 行インデックスと列インデックスの範囲を指定して抽出
| # 0番目から1番目の行、0番目から1番目の列を抽出 print(df.iloc[0:2, 0:2]) |

まとめ
次回も引き続きpandasを扱います。外部ファイルからのデータ読み込みとデータ整形について説明します。データ解析では、さまざまな形式のファイルからデータを取り込むことが一般的です。さらに、データ整形は解析品質に大きく影響する要素で、効率的かつ適切にデータを整形することが、分析結果に重要な影響を与えます。具体的なコード例とともに説明しますので、次回もお楽しみに。